

Introducing intelligent recommendations
Optimized for mobile and desktop
When we started this project, the overall goal was to improve the follow-on viewership significantly. We set three goals:
- optimize the experience for both desktop and mobile
- build an algorithm that works well for small and large datasets
- ensure GDPR compliance and protect privacy.
We found two recommended videos to be the best choice for mobile and four recommendations on bigger screens. It seemed that by adding more recommendations did not result in higher viewership but instead made it more difficult to chose something.
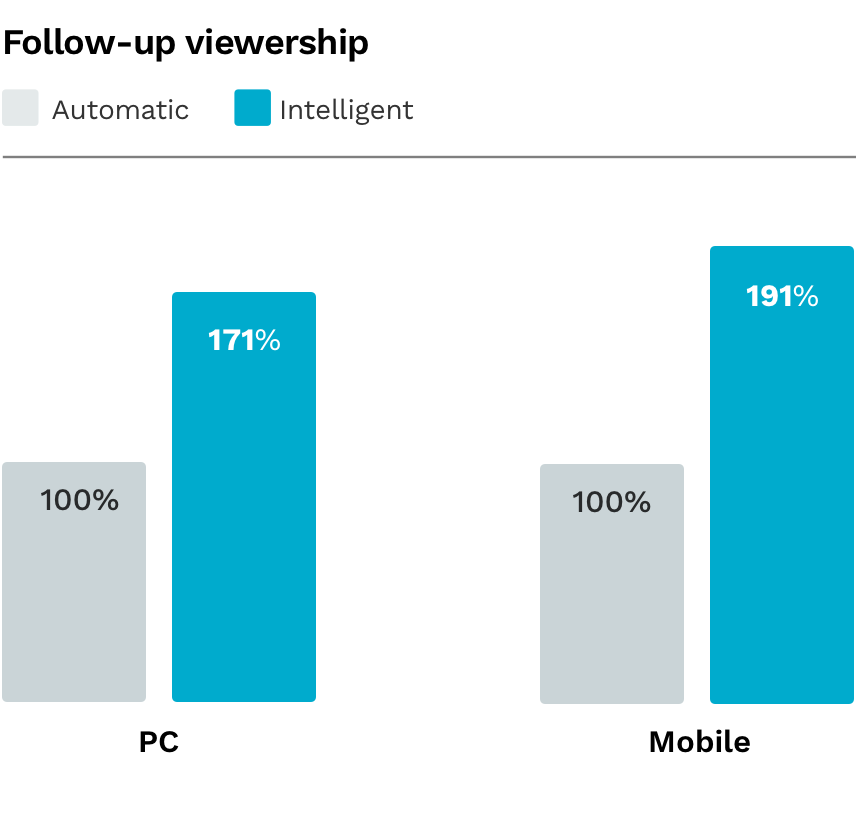
During the initial tests we saw an increase of a stunning 71% of follow-on viewership on desktop and an increase of 91% on mobile.
The algorithm
The goal of our recommendation engine was to be able to work well with both small and large datasets. We do this by utilizing information from the content and by looking at how popular the video is. Previously we have used automatic playlists to make recommendations based on one of the following content in the same category, the most recent content, or the most viewed content. However, we realized that this was far from optimal, and wanted to improve further.
One of the most common approaches to recommendation systems used today is called collaborative filtering where you present a set of candidate videos for a specific video (the "seed video") and then track which candidates have the highest selection rate. This algorithm performs well when both the seed and the candidate videos are watched in sequence in large quantities over long periods.
Unfortunately, not everyone reaches millions of video views and thus can benefit from collaborative filtering. In addition to the drawback that you need an extensive data set to make collaborative filtering work, it is also static, and hence not that well suited if you consistently publish a lot of new and relevant content where the value of each video diminishes over time. Having a recommendation system that accumulates over time makes the recommendations worse as the historic inertia can prohibit new content from surfacing.
To give an example, you can think about the Netflix recommendation engine. This sophisticated engine uses many other mechanisms than just collaborative filtering so that the recommendations stay relevant for extended periods. The classic movies are still relevant and watched even today despite being 20 years old.
Compare this with the recommendation engine required by a news agency like CBS or a weather channel like AccuWeather who produce new material every day and where the shelf life of content is extremely short, especially in the case of weather forecasts.
The Google paper
Eventually, we took inspiration from a research paper by Google talking about some of the challenges with collaborative filtering and how to improve it with content and viewership data. We based our algorithm on both the content inside of the videos represented as tags as well as the popularity of the content. Since we wanted the algorithm to work also for small sample sets, we used the "overall recent popularity" as a proxy for relevancy. A set of recommendations for a video usually requires several days worth of data, which is too slow, especially for news content.
The content tags can be added manually based on editorial preferences. We also put in place an innovative system that uses machine learning to scan the videos and find the correct content tags from within the videos. The entire set of content tags returned from the video is then analyzed, evaluated, and aggregated into meaningful tags based on which keywords are relevant. For example, if you have a video of two people being interviewed, a machine learning algorithm would correctly recognize tags such as human, woman, and man, but those provide little value to a content recommendation system. Instead, other tags, such as accident and fire, would be more meaningful if the video is an interview with a fireman about a gas pipeline that exploded and caused a fire.
We are still in the early stages here, but excited about the future!
Ensure GDPR compliance and protect privacy
We have customers all around the world and see a strong trend towards more privacy and protection of user information. When faced with the decision whether we should do some form of cookie tracking on the user side to get even better data, we opted not to do it to ensure that we respect user privacy and full GDPR compliancy. We believe this is a more future proof choice and something that our customers value.
The results
During the initial trials, we were positively surprised with the results as we saw an increase of a stunning 71% of follow-on viewership on desktop, and an increase of 91% on mobile. We aim to improve this even further with content tagging and platform-specific parameters.
Intelligent recommendations are rolled out to Flowplayer customers over the next months. Content tagging is available for Enterprise clients as an opt-in beta program, and you can reach out to us if you want to take part.